Tìm hiểu về thư viện keras trong deep learning

Keras là một library được phát triển vào năm 2015 bởi François Chollet, là một kỹ sư nghiên cứu deep learning tại google. Nó là một open source cho neural network được viết bởi ngôn ngữ python. keras là một API bậc cao có thể sử dụng chung với các thư viện deep learning nổi tiếng như tensorflow(được phát triển bởi gg), CNTK(được phát triển bởi microsoft),theano(người phát triển chính Yoshua Bengio). keras có một số ưu điểm như :
- Dễ sử dụng,xây dựng model nhanh.
- Có thể run trên cả cpu và gpu
- Hỗ trợ xây dựng CNN , RNN và có thể kết hợp cả 2.*
Cách cài đặt :
Trước khi cài đặt keras bạn phải cài đặt một trong số các thư viện sau tensorflow,CNTK,theano. Sau đó bạn có thể cài đặt bằng 1 số lệnh sau đối với window:
- pip install keras
- conda install keras
Tìm hiểu cấu trúc của Keras
Cấu trúc của keras chúng ta có thể chia ra thành 3 phần chính :
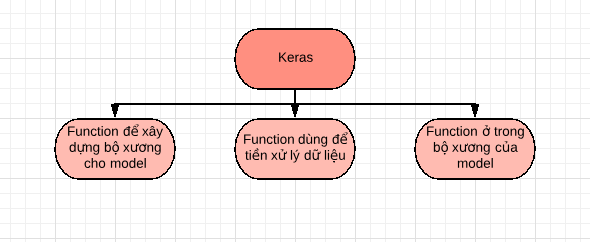
Đầu tiền là các module dùng để xây dựng bộ xương cho model :
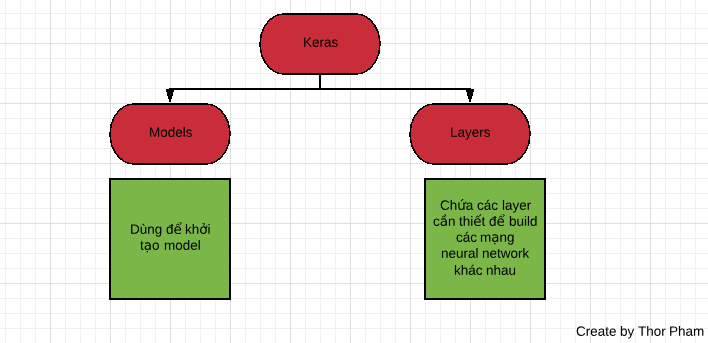
Đầu tiên ta tìm hiểu sub-module : Models trong keras. Để khởi tạo một model trong keras ta có thể dùng 2 cách:
- Cách 1 : Thông qua Sequential như ví dụ dưới. Chúng ta khởi tạo model bằng
Sequentialsau đó dùng method add để thêm các layer.
import numpy as np
from keras.models import Sequential,Model
model = Sequential()
model.add(Conv2D(32, kernel_size=(3, 3),
activation='relu',
input_shape=input_shape))
model.add(Flatten())
model.add(Dense(128, activation='relu'))
model.add(Dense(num_classes, activation='softmax'))
model.compile(loss=keras.losses.categorical_crossentropy,
optimizer=keras.optimizers.Adadelta(),
metrics=['accuracy'])
model.fit(x_train, y_train,
batch_size=batch_size,
epochs=epochs,
verbose=1,
validation_data=(x_test, y_test))
- Cách thứ 2 để khởi tạo model là dùng function API . Như ví dụ dưới
from keras.models import Model
from keras.layers import Input, Dense
a = Input(shape=(32,))
b = Dense(32)(a)
model = Model(inputs=a, outputs=b)
- Nó cũng tương tự như computation graph, chúng ta xem input cũng là một layer sau đó build từ input tới output sau đó kết hợp lại bằng hàm
Model. Ưu điểm của phương pháp này có thể tùy biến nhiều hơn,giúp ta xây dựng các model phức tạp nhiều input và output. - Khi chúng ta khởi tạo một model thì có các method ta cần lưu ý là :
compile: Sau khi build model xong thì compile nó có tác dụng biên tập lại toàn bộ model của chúng ta đã build. Ở đây chúng ta có thể chọn các tham số để training model như : thuật toán training thông qua tham sốoptimizer, function loss của model chúng ta có thể sử dụng mặc định hoặc tự build thông qua tham sốloss, chọn metrics hiện thị khi model được trainingsummarymethod này giúp chúng ta tổng hợp lại model xem model có bao nhiêu layer, tổng số tham số bao nhiêu,shape của mỗi layer..fitdùng để đưa data vào training để tìm tham số model(tương tự như sklearn)predictdùng để predict các new instanceevaluateđể tính toán độ chính xác của modelhistorydùng để xem accuracy,loss qua từng epochs . Thường dùng với matplotlib để vẽ chart.
Tiếp theo chúng ta tìm hiểu đên sub-module Layers : Nó chứa các layers chuyên dụng để ta build các model như CNN,RNN,GANs..Có rất nhiều layers nên ta chỉ quan tâm đến một số layer thường sử dụng.
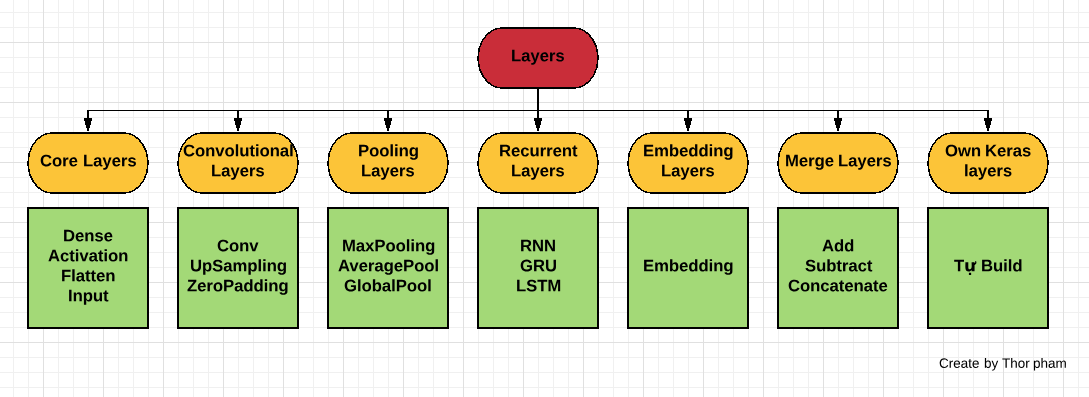
Core layer : chứa các layer mà hầu như model nào cũng sử dụng đến nó.
Denselayer này sử dụng như một layer neural network bình thường. Các tham số quan tâm.unitschiều outputactivationdùng để chọn activation.input_dimchiều input nếu là layer đầu tiênuse_biascó sử dụng bias ko,true or falsekernel_initializerkhởi tạo giá trị đầu cho tham số trong layer trừ biasbias_initializerkhởi tạo giá trị đầu cho biaskernel_regularizerregularizer cho coeffbias_regularizerregularizer cho biasactivity_regularizercó sử dụng regularizer cho output kokernel_constraint,bias_constraintcó ràng buộc về weight ko
Activationdùng để chọn activation trong layer(có thể dùng tham số activation thay thế).Xem phần sau.Dropoutlayer này dùng như regularization cho các layer hạn chế overfiting. Tham số cần chú ý :ratetỉ lệ dropoutnoise_shapecái này chưa tìm hiểuseedrandom seed bình thường
Flattendùng để lát phằng layer để fully connection, vd : shape : 20x20 qua layer này sẽ là 400x1Inputlayer này sử dụng input như 1 layer như vd trước ta đã nói.Reshapegiống như tên gọi của nó, dùng để reshapeLambdadùng như lambda trong python thôi ha- Convolutional Layers: chứa các layer trong mạng nơ ron tích chập .
Conv1D,Conv2Dlà convolution layer dùng để lấy feature từ image. tham số cần chú ý:filterssố filter của convolution layerkernel_sizesize window search trên imagestridesbước nhảy mỗi window searchpaddingsame là dùng padding,valid là kodata_formatformat channel ở đầu hay cuối
UpSampling1D,UpSampling2DNgược lại với convolution layersizevd (2,2) có nghĩa mỗi pixel ban đầu sẽ thành 4 pixelZeroPadding1D,ZeroPadding2Ddùng để padding trên image.paddingsố pixel padding
- Pooling Layers : Chứa các layer dùng trong mạng CNN.
MaxPooling1D,MaxPooling2Ddùng để lấy feature nổi bật(dùng max) và giúp giảm parameter khi trainingpool_sizesize poolingAveragePooling1D,AveragePooling2Dgiống như maxpooling nhưng dùng Average
GlobalMaxPooling1D,GlobalMaxPooling2Dchưa dùng bao giờ nên chưa hiểu nó làm gì- Recurrent Layers chứa các layers dùng trong mạng RNN
RNNlayer RNN cơ bảnGRUkhắc phục hạn chế RNN tránh vanish gradient.LSTMLong Short-Term Memory layer
- Embedding layer :
Embeddingdùng trong nhiều trong nlp mục đích embbding sang một không gian mới có chiều nhỏ hơn, và dc learning from data thay cho one-hot lad hard code.input_dimsize của vocabularyoutput_dimsize của word embbdinginput_lengthchiều dài mỗi sequence
- Merge Layers chứa các layers giúp chúng ta cộng,trừ,hoặc nối các layer như các vector vậy :
Addcộng các layersSubtracttrừ các layersMultiplynhân các layerAveragetính trung bình các layersMaximumlấy maximun giữa các layersConcatenatenối các layer
DotNhân matrix giữ 2 layers Own Keras layers : Giúp chúng ta có thể xây dựng layer như theo ý muốn, gồm 3 method chúng ta cần chú ý làbuild,callvàcompute_output_shape
from keras import backend as K
from keras.engine.topology import Layer
import numpy as np
class MyLayer(Layer):
def __init__(self, output_dim, **kwargs):
self.output_dim = output_dim
super(MyLayer, self).__init__(**kwargs)
def build(self, input_shape):
# Create a trainable weight variable for this layer.
self.kernel = self.add_weight(name='kernel',
shape=(input_shape[1], self.output_dim),
initializer='uniform',
trainable=True)
super(MyLayer, self).build(input_shape) # Be sure to call this at the end
def call(self, x):
return K.dot(x, self.kernel)
def compute_output_shape(self, input_shape):
return (input_shape[0], self.output_dim)
Tiếp theo chúng ta tìm hiểu đến tiền xử lý dữ liệu trong keras, nó được chia ra làm 3 phần :
Sequence Preprocessingtiền xử lý chuỗi .TimeseriesGeneratorcái này dùng để tạo dữ liệu cho time seriespad_sequencesdùng để padding giúp các chuỗi có độ dài bằng nhauskipgramstạo data trong model skip gram,kết quả trả về 2 tuple nếu word xuất hiện cùng nhau là 1 nếu ko là 0.
Text Preprocessingtiền xử lý textTokenizergiống kỹ thuật tokenizer trong nlp, tạo tokenizer từ docummentone_hottạo data dạng one hot encodingtext_to_word_sequencecovert text thành sequence
Image Preprocessingtiền xử lý imageImageDataGeneratortạo thêm data bằng cách scale,rotation...
Các function trong bộ xương của model
Các hàm loss functions thường dùng :
mean_squared_errorthường dùng trong regression tính theo eculicmean_absolute_errortính theo trị tuyệt đốicategorical_crossentropydùng trong classifier nhiều classbinary_crossentropydùng trong classifier 2 classkullback_leibler_divergencedùng để tính loss giữa phân phối thực tế và thực nghiệm
metrics nó là thước đo để ta đánh giá accuracy của model :
binary_accuracynếu y_true==y_pre thì trả về 1 ngược lại 0,dùng cho 2 classcategorical_accuracytương tự binary_accuracy nhưng cho nhiều class
optimizers dùng để chọn thuật toán training.
SGDStochastic gradient descent optimizerRMSpropRMSProp optimizerAdamAdam optimizer
activations để chọn activation function
linearnhư trong linear regressionsoftmaxdùng trong multi classifierrelumax(0,x) dùng trong các layer cnn,rnn để giảm chi phí tính toántanhrange (-1,1)Sigmoidrange (0,1) dùng nhiều trong binary class
Callbacks : khi model chúng ta lớn có khi training thì gặp sự cố ta muốn lưu lại model để chạy lại thì callback giúp t làm điều này :
ModelCheckpointlưu lại model sau mỗi epochEarlyStoppingstop training khi training ko cải thiện modelReduceLROnPlateaugiảm learning mỗi khi metrics ko được cải thiện
Datasets. Keras hỗ trợ một số dataset theo công thức :
cifar100gồm 50,000 32x32 color training images, labeled over 100 categories, and 10,000 test images.mnistdata 70k image data hand written.fashion_mnistDataset of 70k 28x28 grayscale images of 10 fashion categoriesimdb25,000 movies reviews from IMDB, label đánh theo pos/negreuters11,228 newswires from Reuters, labeled over 46 topicsboston_housingdata giá nhà ở boston theo 13 features
from keras.datasets import name_data
(X_train,X_test),(y_train,y_test) = name_data.load_data()
Applications chứa các pre-training weight của các model deep learning nổi tiếng.Xception,VGG16,VGG19,resnet50,inceptionv3,
InceptionResNetV2,MobileNet,DenseNet,NASNet cẩu trúc chung như sau :
preprocess_inputdùng để preprocessing input custom same với input của pretrainingdecode_predictionsdùng để xem label predict
from keras.applications.name_pre_train import Name_pre_train
from keras.applications.name_pre_train import preprocess_input, decode_predictions
model = Name_pre_train(weights='tên dataset')
backends banckend có nghĩa là thay vì keras xây dựng từ đầu các công thức từ đơn giản đến phức tạp, thì nó dùng những thư viện đã xây dựng sẵn rồi và dùng thôi. Giúp tiết kiệm dc thời gian và chí phí. Trong keras có hỗ trợ 3 backend là tensorflow,theano và CNTK.
initializers khởi tạo giá trị weight của coeff và bias trước khi training lần lượt kernel_initializer and bias_initializer. mặc định là glorot_uniform phân phối uniform với giá trị 1/căn(input+output).
regularizers Dùng để phạt những coeff nào tác động quá mạnh vào mỗi layer thường dùng là L1 và L2
constraints dùng để thiết lập các điều kiện ràng buộc khi training
visualization giúp chúng ta plot lại cấu trúc mạng neral network.
Utils chứa các function cần thiết giúp ta xử lý data nhanh hơn.
normalize chuẩn hóa data theo L2
plot_model giúp chúng ta plot model
to_categorical covert class sang binary class matrix